
Disclaimer: This post reflects my own synthesis and perspective on publicly available Cloudflare research and announcements — it does not represent an official Cloudflare position.
TL;DR — AI crawlers now represent a structural threat to how the web creates and distributes value. They consume content at massive scale, send little traffic back, and are quietly degrading CDN performance for real users. This post covers how Cloudflare is responding — not just with bot controls, but with a coherent platform: cryptographic bot identity (co-authored as an IETF standard), content monetization via Pay Per Crawl, token-efficient delivery for agents, a pub/sub AI Index to replace blind crawling, AI-aware cache architecture, and a secure execution layer for agentic code. Each piece reinforces the others. Together they represent Cloudflare’s answer to the question: what should the AI-era internet actually look like?
I spend a lot of time talking with customers about AI. Not just about AI security, or how to block bad bots — but about a deeper, more structural question that most organizations haven’t fully confronted yet: what happens to your business when AI becomes the dominant way people discover information online?
That shift is no longer hypothetical. It is already underway. And at Cloudflare, we have a front-row seat to witness it — at a scale no one else can match.
The Crawl-to-Click Gap Nobody Talks About
Let me start with a number that should make every publisher, SaaS company, and content-driven business pause: 32% of all traffic across Cloudflare’s global network is now automated. Search engine crawlers, uptime monitors, ad networks — and increasingly, AI assistants sweeping the web to fuel their knowledge bases and power their answers.
For decades, this worked on a kind of gentleman’s agreement. Search engines crawled your site, indexed it, and sent humans back to you. Clicks meant ad revenue. The whole SEO industry was built around that loop.
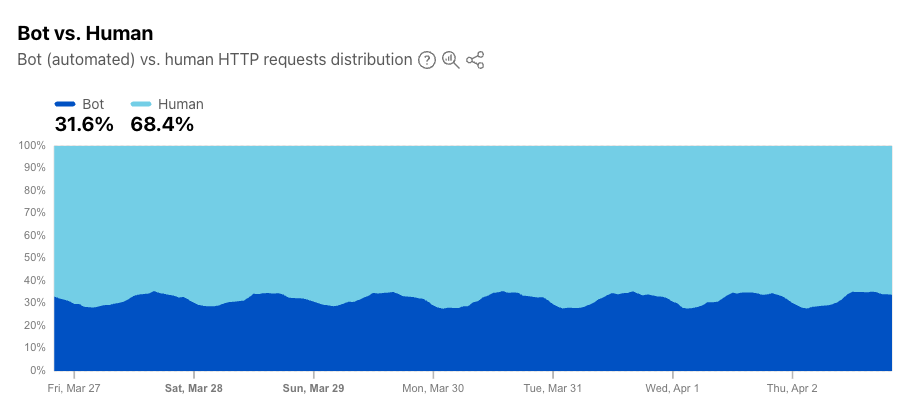
Source: https://radar.cloudflare.com/traffic#bot-vs-human (03/04/2026)
AI broke the loop quietly.
When a user asks an AI chatbot a question that used to go to Google, they often get a complete answer — and never click through to the original source. The AI platform extracted the value. The publisher that created the content got nothing.
Cloudflare data confirms the scale of this: AI training crawlers account for nearly 80% of all AI bot traffic we see — far outpacing search-related activity. They don’t come for a quick index. They sweep entire websites, going deep into long-tail pages that human visitors rarely touch, harvesting training data for the next generation of models. And they send almost no traffic back in return.
This is what we call the crawl-to-click gap. It is real, it is growing, and ignoring it is no longer an option.
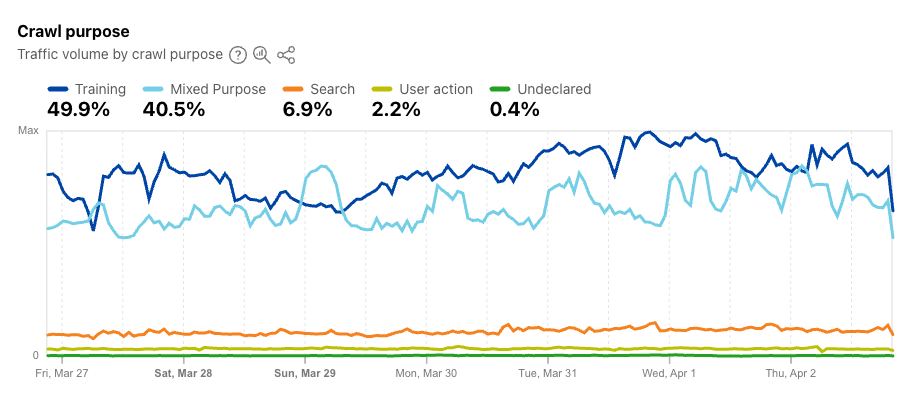
Source: https://radar.cloudflare.com/ai-insights#crawl-purpose (03/04/2026)
It Gets Worse: AI Is Breaking Your Infrastructure Too
There’s a less visible — but increasingly urgent — dimension to this problem: AI crawlers are degrading CDN cache performance for human users.
Traditional cache architectures were designed around how humans browse the web. Popular pages get cached at the edge. Less popular content gets served from further back. The system self-tunes over time. It works beautifully for the traffic it was designed for.
AI crawlers behave nothing like that. Rather than concentrating on popular pages, they methodically scan entire sites — including content that human visitors almost never request. Over 90% of pages ingested in large training jobs are unique by content. AI crawlers don’t share browser sessions or benefit from cached resources the way human visitors do. They can run multiple independent instances in parallel, each appearing to the CDN as a brand-new visitor.
The result is a systematic destruction of the cache efficiency that human traffic depends on.
Real-world consequences are already documented: Wikipedia recorded a 50% jump in multimedia bandwidth consumption driven by AI bots bulk-scraping images for training datasets. Developer platforms like SourceHut and Read the Docs experienced degraded response times and unexpected bandwidth spikes from bots repeatedly downloading large files. In nearly every case, the only available mitigation was a blunt one — block all AI traffic, forfeiting any potential benefit.
The industry needs smarter answers. Cloudflare is building them.
The Trust Problem Underneath Everything
Here’s something that gets overlooked in most conversations about AI bots: before you can control, monetize, or even correctly classify a bot, you have to be able to trust that it is who it says it is.
Today’s bot identification methods are surprisingly fragile. A crawler can announce itself via its User-Agent header — but that header is trivially spoofed. Any actor can claim to be GPTBot or ClaudeBot. The alternative is to validate IP address ranges published by the crawler’s operator — but IP ranges are brittle. They change as cloud infrastructure evolves, are shared across multiple services on the same provider, and fall apart entirely when traffic routes through VPNs or privacy proxies.
This isn’t a theoretical vulnerability. It means that even a well-intentioned blocking or monetization policy can be defeated by anyone willing to forge a header.
Cloudflare’s answer is Web Bot Auth — a cryptographic identity framework for bots and agents. Instead of trusting declarations that can be faked, the proposal requires agents to prove who they are by signing their requests using a public/private key pair. The underlying mechanism is RFC 9421 (HTTP Message Signatures), a published internet standard for cryptographic request authentication.
The way it works: an agent generates an Ed25519 key pair and hosts its public key at a discoverable URL — its Signature-Agent directory. When making a request, the agent signs the target domain, includes a validity window and a key identifier, and attaches a web-bot-auth tag to declare the purpose. Cloudflare, acting as a reverse proxy, validates the signature against the published public key and confirms or rejects the bot’s identity.
No shared secrets. No IP list maintenance. No spoofable headers. Cryptographic proof.
What makes this particularly significant is where Cloudflare sits in this story: not as an adopter of someone else’s standard, but as a co-author of new ones. Cloudflare researchers have filed Internet Drafts at the IETF — the body that defines how the internet works — specifically proposing the web-bot-auth architecture and the signature-agent directory mechanism as open standards. This is Cloudflare helping write the rulebook for the AI internet.
The industry is already moving in this direction: OpenAI has adopted RFC 9421 for their Operator product, cryptographically signing all outgoing agent requests so that any site operator can independently verify their authenticity. This is the kind of broad adoption that turns a proposal into a standard.
For customers, the practical implication is significant: a verified identity layer makes every other AI capability more powerful. You can’t reliably charge a crawler you can’t verify. You can’t build a fair content marketplace without provable identities. Web Bot Auth is the cryptographic foundation the rest of the ecosystem stands on.
What Cloudflare Is Building — And Why This Isn’t Just Bot Management
When I explain Cloudflare’s AI platform to customers, the first reaction is often: “Oh, you mean like blocking AI crawlers?”
Not exactly. Or rather — not only.
Yes, Cloudflare was among the first to give customers granular, one-click control over AI bots as a distinct category: block, allow, or challenge specific crawlers by purpose — training, search, or real-time user-triggered — with zero engineering effort. That is the foundation.
What’s built on top of that foundation is where things get genuinely interesting.
Pay Per Crawl: Reviving HTTP 402
Most people have never encountered HTTP status code 402. It appeared in the original HTTP specification as “Payment Required” and was largely forgotten for three decades. Cloudflare brought it back to life.
Pay Per Crawl gives content owners a third path beyond “block everything” or “give your work away for free.” Content owners set a price per access. AI crawlers can either receive a 402 response and decide whether to pay, or proactively declare their maximum willingness to pay upfront. Cloudflare handles the billing relationship as merchant of record — no individual contracts, no scale requirements.
The Web Bot Auth cryptographic identity layer is what makes this trustworthy. Because crawlers authenticate via signed requests, Cloudflare can tie billing events to verified identities — not just IP addresses or self-declared headers that anyone can forge. The payment relationship has genuine integrity.
The forward-looking dimension matters too. As AI agents evolve from content scrapers into autonomous actors with budgets of their own, HTTP 402 becomes their native protocol for programmatic content negotiation. Pay Per Crawl is built for today’s crawlers and designed for tomorrow’s agents.
Markdown for Agents: Treating Agents as First-Class Citizens
Here is a data point worth sitting with: a typical blog post served as HTML might cost over 16,000 tokens when fed to an AI model. The same content served as clean Markdown can be delivered in roughly 3,000 tokens — an 80% reduction. The difference comes from stripping out navigation bars, script tags, class attributes, and all the structural noise that HTML accumulates to serve human browsers.
Cloudflare’s network can now perform this conversion in real time at the edge, triggered by a content negotiation header. An AI agent that sends Accept: text/markdown in its request receives a clean, structured response — along with a header indicating the token count and signals declaring how the content may be used: for training, search, or inference.
No backend changes. No new pipelines. A single dashboard toggle, available today in beta on Pro, Business, and Enterprise plans. This is what it looks like to treat agents as first-class citizens of the web.
AI Index: From Crawling to Subscribing
The most architecturally forward-looking piece of what Cloudflare is building is the AI Index.
The premise: rather than AI platforms dispatching blind crawlers across the open web, site owners create a structured, AI-optimized index of their content that they own and control. Cloudflare manages the underlying infrastructure — embeddings, chunking, vector search, structured APIs. What the site owner gets in return is a ready-made interface for AI builders: an MCP server, an LLMs.txt file, a search API, bulk data endpoints, and pub/sub subscriptions that deliver real-time updates whenever content changes.
That last element is the architectural shift. Instead of re-crawling to discover what’s new, AI builders subscribe to updates. Fresher data, lower infrastructure costs, and a permissioned relationship between creator and consumer. An aggregated Open Index bundles participating sites for broader discovery — with content quality metadata (uniqueness, depth, relevance) that lets buyers evaluate value before paying for access.
This is the blueprint for a healthier content ecosystem: one where value flows in both directions, and creators retain meaningful control.
AI-Aware Caching: Infrastructure Research at the Frontier
In collaboration with researchers at ETH Zurich, Cloudflare produced a peer-reviewed paper published at the 2025 ACM Symposium on Cloud Computing examining how AI crawler behavior impacts CDN cache performance. The findings confirmed what operators were experiencing in practice: AI and human traffic have fundamentally incompatible cache characteristics, and mixing them without architectural changes degrades performance for human users.
The research points toward dedicated cache tiers for AI versus human traffic, alternative eviction algorithms (SIEVE and S3FIFO show early promise), and machine learning-based policies that adapt to real-time traffic composition. Cloudflare is already applying early findings to reduce bandwidth costs for customers experiencing disproportionate AI traffic — with more architectural changes ahead.
Dynamic Workers: The Execution Layer for the Agentic Era
When AI agents move from reading content to taking action — writing scripts, calling APIs, processing data on your behalf — they need somewhere safe to run. The current default answer is containers. Containers work, but they’re heavy: hundreds of milliseconds to start, hundreds of megabytes per instance. At the scale where every user might run multiple simultaneous agents, that cost structure doesn’t hold.
Dynamic Workers address this with Cloudflare’s isolate-based sandbox model — the same technology powering Cloudflare Workers for nearly a decade. An isolate starts in milliseconds, uses a few megabytes, and scales to millions of concurrent sandboxes with no pre-warming and full per-request isolation. That’s roughly 100 times faster than a typical container.
Paired with Code Mode — where agents write TypeScript functions against typed APIs rather than navigating hundreds of tool definitions — the entire Cloudflare API surface becomes accessible from an agent in under 1,000 tokens. Context windows stay lean. Agents perform better.
How These Pieces Fit Together
What makes Cloudflare’s approach genuinely distinctive is not any individual capability in isolation. It is that these layers form a coherent, mutually reinforcing platform:
- Web Bot Auth provides the cryptographic identity layer — verified, unforgeable, standardized at the IETF.
- AI Crawl Control uses that identity to classify and route AI traffic with precision.
- Pay Per Crawl converts verified AI traffic into a commercial relationship.
- Markdown for Agents ensures that traffic you choose to serve is delivered efficiently.
- AI Index replaces crawling altogether with a structured, permissioned discovery model.
- AI-Aware Caching protects human user performance as AI traffic scales.
- Dynamic Workers provides the secure execution substrate for agents that act, not just read.
No other company is simultaneously building the identity layer, the protection layer, the monetization layer, the content delivery layer, and the execution layer for the AI era — while co-authoring the open standards that govern all of them, and observing more real AI internet traffic than anyone else on the planet.
The Bottom Line
The internet is being rebuilt around a new class of actors — AI agents that don’t click, don’t generate ad revenue, and are increasingly capable of autonomous action. The transition is already underway. The infrastructure to support it fairly — for humans, for creators, and for AI builders alike — does not yet exist in mature form.
Cloudflare is building it. Not just as a product roadmap, but as active participation in the standards bodies that will define how all of this works for decades. From IETF Internet Drafts on bot authentication architecture, to peer-reviewed cache research at top systems conferences, to an open content signals framework — the work is happening at the foundational level.
We don’t just have a front-row seat to the AI internet. We’re helping build the venue.
This covers one side of the equation: how Cloudflare helps you manage, protect, and monetize the AI traffic that hits your content and infrastructure. But there is a second, equally important question — what about the AI your own teams, developers, and applications are consuming every day? How do you make AI accessible across your organization without losing control of costs, security, or governance? That’s the topic of my next post: AI Consumption at Scale: How Cloudflare Helps You Make AI Work for Your Entire Organization →
I’m a Solutions Engineer at Cloudflare. This post reflects my own synthesis and perspective on publicly available Cloudflare research and announcements — it does not represent an official Cloudflare position.
References: Web Bot Auth & RFC 9421 · AI Crawl Control & Bot Categories · Pay Per Crawl · Markdown for Agents · AI Index · AI-Aware Caching · Dynamic Workers · Crawl/Refer Analysis · Traffic by Purpose & Industry